

Treten Sie ein in die Zukunft der Inhaltserstellung, wo die transformative Kraft von KI-generierten Inhalten Branchen umgestaltet und die Grenzen der Kreativität verschiebt.
Von Nachrichtenartikeln bis hin zu Produktbeschreibungen produzieren KI-Algorithmen riesige Textmengen, die oft den menschlichen Schreibstil imitieren.
Mit dieser Zunahme an maschinell erstellten Inhalten wird jedoch der Bedarf an zuverlässigen KI-Inhaltsdetektoren immer wichtiger.
Diese Detektoren spielen eine wichtige Rolle bei der Unterscheidung zwischen menschlichem und KI-generiertem Text und gewährleisten die Integrität und Authentizität der Inhalte, die wir konsumieren.
Lesen Sie auch: IP-Adressprobleme beheben
In diesem Artikel werden wir uns mit der Bedeutung des KI-Inhaltsdetektors befassen und untersuchen, wie er maschinell erstellten Text erkennt.
Lassen Sie uns also eintauchen und die Geheimnisse hinter diesen leistungsstarken KI-Tools lüften.
Verständnis der KI-Inhaltserkennungstechnologie
Um das Konzept der KI-Inhaltsdetektoren zu verstehen, sollten wir uns ansehen, was hinter den Kulissen passiert. Diese Erkennungsprogramme stützen sich in erster Linie auf die Analyse des Kontextes, der einem bestimmten Wort vorausgeht, um Vorhersagen über KI-generierte Inhalte zu treffen.
Betrachten Sie den Satz,
"Nach einem langen Arbeitstag entspanne ich mich gerne mit einem guten Buch und einer warmen Tasse ___".
Auf der Grundlage eines umfangreichen Trainings mit einem vielfältigen Datensatz von 117 Millionen Datenpunkten hat das KI-Modell, wie das GPT-3-Sprachmodell, eine ausgeprägte Fähigkeit entwickelt, Muster und Verbindungen innerhalb von Wortfolgen zu erkennen.
In diesem speziellen Beispiel wird das Wort "Tee" mit einer Wahrscheinlichkeit von 41 % auf der Grundlage der Trainingsdaten am häufigsten vorhergesagt.
Das KI-Modell greift auf seine Trainingsdaten zurück und untersucht die Muster im Kontext der Wortfolge. Es erkennt, dass auf Wörter wie "Tee" und "Kaffee" häufig das Wort "Tasse" folgt.
Das KI-Modell berechnet auf der Grundlage dieser Muster die Wahrscheinlichkeit, dass jedes Wort das nächste vorhergesagte Wort ist, und trifft so seine Vorhersage.
Wie funktionieren also KI-Inhaltsdetektoren?
Was die Funktionsweise von KI-Inhaltsdetektoren angeht, ist der Prozess relativ simpel.
Gehen wir zur Veranschaulichung dieses Prozesses durch ein Beispiel.
1. Wir beginnen mit der Erstellung eines Artikels oder eines beliebigen Textes mit Hilfe eines KI-Textgenerators. Öffnen Sie einen GPT Writer und erstellen Sie einen Artikel, einen Blogbeitrag oder einen beliebigen Inhalt.

2. Sobald wir den generierten Text haben, können wir seine Originalität mithilfe von KI-Inhaltsdetektoren überprüfen.
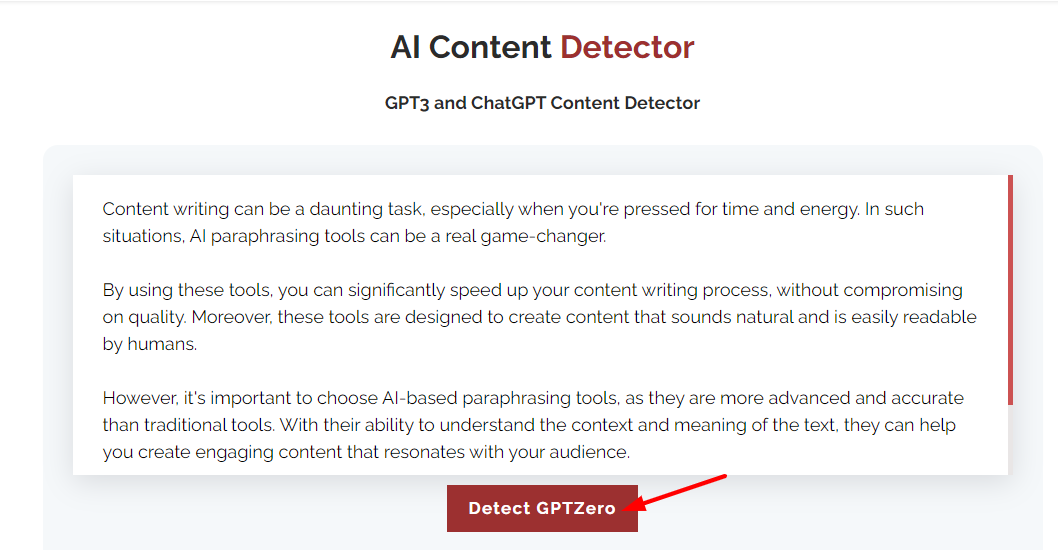
3. Die KI-Inhaltsdetektoren analysieren den Text zunächst Satz für Satz. Sie berechnen Vorhersagen auf der Grundlage von Mustern und Wortkontext.
4. Wenn ein signifikanter Teil des Textes durchgängig die vorhersehbarsten Wörter oder Phrasen auswählt, besteht der Verdacht, dass der Text künstlich generiert sein könnte.
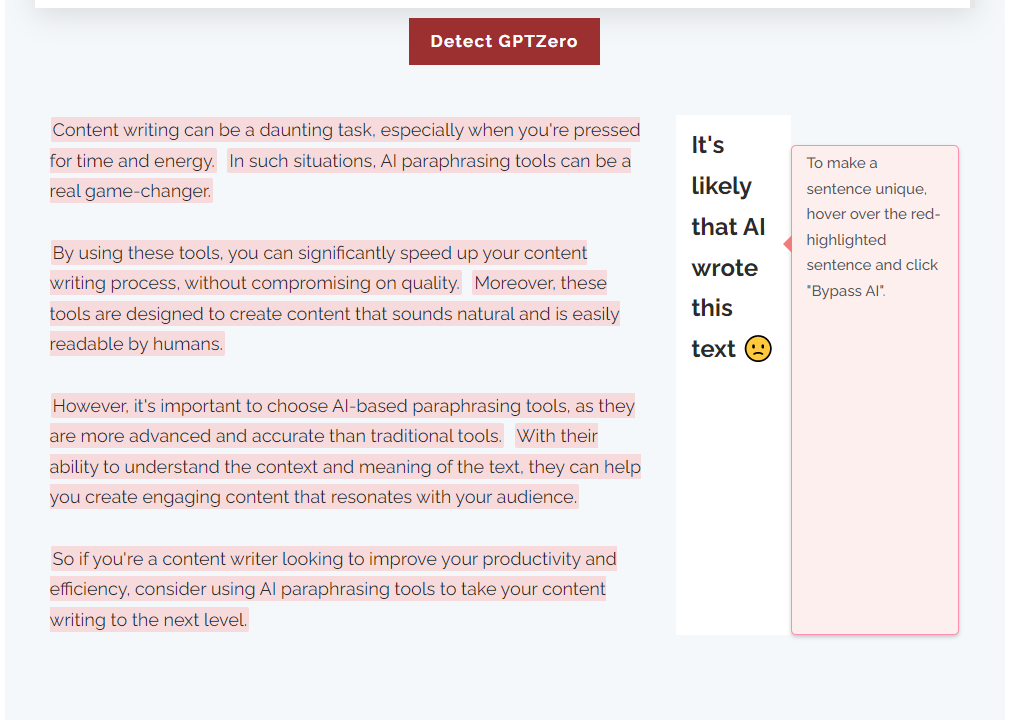
Sehen Sie, wie dieses Tool zur Erkennung von Inhalten den von GPT geschriebenen Inhalt in Sekundenschnelle hervorgehoben hat.
Als Reaktion auf die Erkennung von KI-Inhalten können Sie das Tool zur Umgehung von KI-Inhalten verwenden, um dieses Problem zu beheben.
Dieses KI-Tool nutzt fortschrittliche Techniken, um Inhalte zu generieren, die die Erkennungsalgorithmen der KI-Inhaltsdetektoren umgehen können.
Um KI-geschriebene Sätze einzigartig zu machen, bewegen Sie einfach den Mauszeiger nacheinander über die rot hervorgehobenen Sätze und klicken Sie auf "KI umgehen".
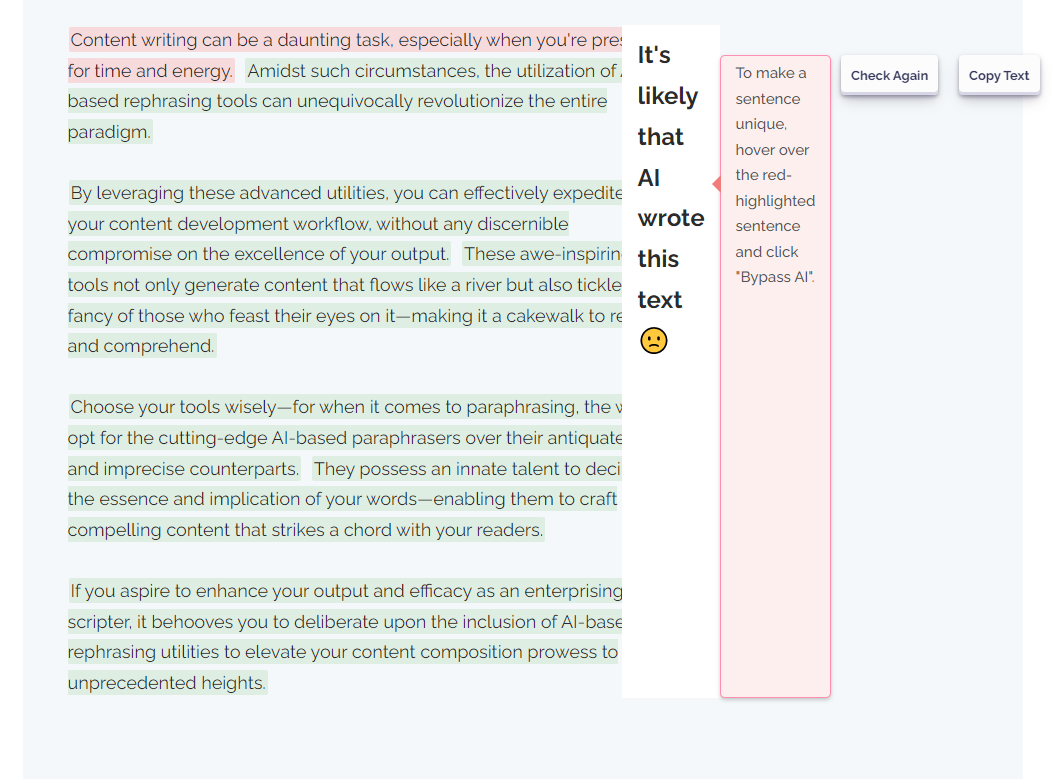
Jetzt können Sie den Inhalt noch einmal auf KI-Erkennung prüfen, um sicherzustellen, dass er nun einzigartig und originell ist. Klicken Sie einfach auf "erneut prüfen" und sehen Sie sich die Ergebnisse an:
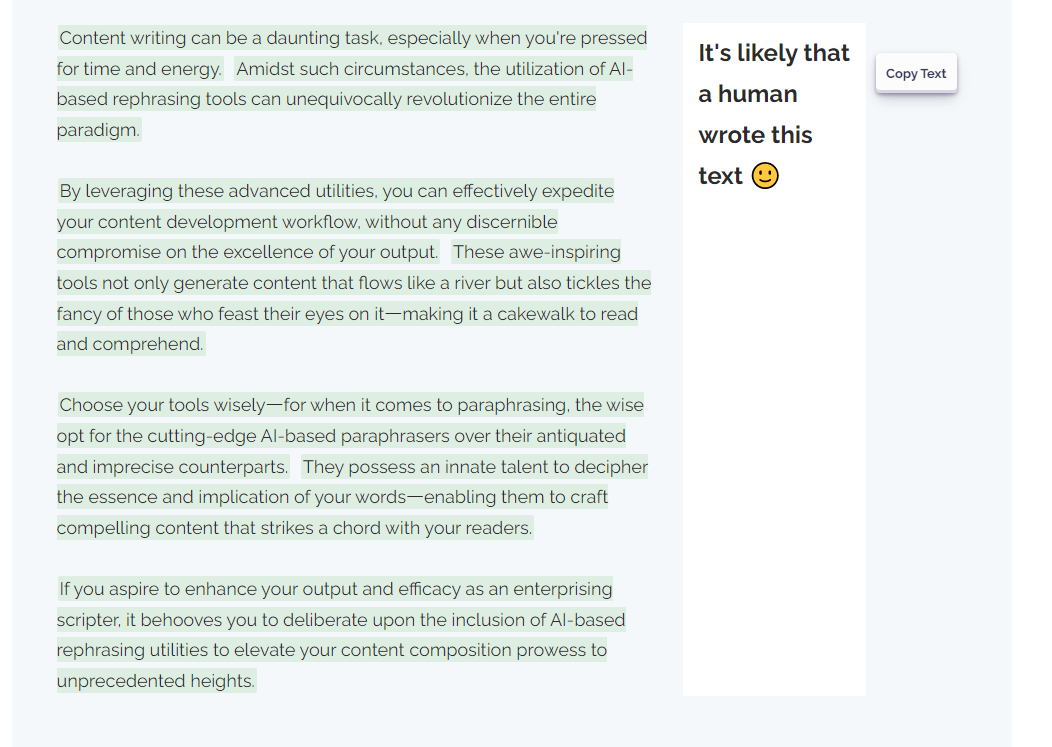
Randbemerkung
Es ist wichtig zu wissen, dass authentische menschliche Texte in der Regel komplex sind und eine unvorhersehbare und kreative Sprache verwenden. Diese natürliche Variation unterscheidet sie von maschinell erstellten Inhalten.
Die größten Herausforderungen bei der genauen Erkennung von Inhalten
Trotz der Fortschritte bei der Erkennung von KI-Inhalten gibt es noch einige Herausforderungen zu bewältigen.
Die zunehmende Komplexität von Sprachmodellen bedeutet, dass die Vorhersagefähigkeiten der KI die Unterscheidung zwischen menschlichem und maschinell erstelltem Text erschweren.
Mit der wachsenden Menge an Trainingsdaten nimmt auch die Variabilität der von KI generierten Inhalte zu, was den Erkennungsprozess erschwert.
Die Analyse großer Textabschnitte nach der prädiktiven Regenerationsfähigkeit von KI-Modellen kann Aufschluss geben.
Wenn ein Text in der Stichprobe durchgängig auf die vorhersehbarsten Wörter in den Absätzen zurückgreift, ist er wahrscheinlich maschinell generiert.
Im Gegensatz dazu verwenden erfahrene menschliche Autoren oft eine komplexe Sprache und liefern unvorhersehbare Erklärungen, wodurch sich ihre Arbeit von der künstlichen Schrift unterscheidet.
Die derzeitige Methode zur Erkennung von KI-generierten Inhalten auf der Grundlage des Wortkontexts ist zwar relativ einfach, aber die ständigen Fortschritte in der KI-Technologie erfordern kontinuierliche Forschung und Anpassung, um maschinell generierten Text effektiv zu erkennen.
Wenn wir das Konzept, die Funktionsweise und die Herausforderungen der Erkennung von KI-Inhalten verstehen, erhalten wir wertvolle Einblicke in die faszinierende Welt der automatischen Inhaltserstellung.
Grenzen und Schwächen der KI-Detektion: Beispiele aus der Praxis
Trotz erheblicher Fortschritte sind KI-Erkennungstools nicht vor Fehlern gefeit und können ungenaue Ergebnisse und falsch positive Ergebnisse liefern.
Denken Sie an einen Studenten, der aufgrund eines unzuverlässigen KI-Inhaltsdetektors fälschlicherweise beschuldigt wurde, bei seiner Geschichtsprüfung zu schummeln.
Dieser unglückliche Vorfall wirft ein Licht auf die Grenzen und den potenziellen Schaden, der entsteht, wenn man sich ausschließlich auf diese Technologien verlässt, um zwischen von Menschen erstellten Inhalten und KI-generierten Inhalten zu unterscheiden.
Sehen wir uns nun einige andere häufige Szenarien an, in denen die KI-Erkennung versagt:
1. Moderation in sozialen Medien
Bekannte Plattformen wie Facebook und Twitter setzen KI-gestützte Software ein, um unangemessene oder schädliche Inhalte zu erkennen und zu markieren. Diese Systeme stufen jedoch oft fälschlicherweise unschuldige Beiträge als Verstöße ein und lassen bösartige Inhalte unerkannt, was ihre Wirksamkeit untergräbt.
2. Bildungseinrichtungen
Viele Schulen verlassen sich auf Plagiatsprüfsysteme, die Algorithmen des maschinellen Lernens verwenden, um Fälle von kopierten Arbeiten zu erkennen. Leider erkennen diese Systeme gelegentlich Originalarbeiten fälschlicherweise als Plagiate, was zu unbegründeten Anschuldigungen gegen Studenten führt und deren akademischem Ruf schaden kann.
3. Einstellungsprozesse
Unternehmen integrieren zunehmend Tools zur Verarbeitung natürlicher Sprache (NLP) in ihre Einstellungsverfahren. Wenn diese Tools jedoch nicht in der Lage sind, bestimmte Dialekte oder kulturelle Nuancen in den eingereichten Dokumenten zu erkennen, können sie ungewollt bestimmte Bewerber diskriminieren. Dies unterstreicht, wie wichtig es ist, sicherzustellen, dass KI-Detektoren für verschiedene sprachliche und kulturelle Variationen empfänglich sind.
Diese Beispiele aus der Praxis zeigen die Schwächen und Grenzen von KI-Erkennungssystemen.
Auch wenn diese Technologien eine wertvolle Hilfe darstellen, ist es wichtig, ihre Schwächen zu erkennen und an der Verbesserung ihrer Genauigkeit und Zuverlässigkeit zu arbeiten.
Ein ausgewogenes Verhältnis zwischen KI-Unterstützung und menschlichem Urteilsvermögen kann dazu beitragen, die Risiken zu mindern und faire Ergebnisse in verschiedenen Bereichen zu gewährleisten, in denen KI-Erkennung eingesetzt wird.
Gründe für die Grenzen von KI-Inhaltsdetektoren
Faszinierend ist, dass KI-Inhaltserkennungs-Tools KI nutzen, um KI-generierte Inhalte zu identifizieren. Warum bleiben diese scheinbar fortschrittlichen Tools zur Erkennung von KI-Inhalten manchmal hinter den Erwartungen zurück? Finden wir es heraus.
1. Unzureichende Trainingsdaten
KI-Inhaltserkennungsprogramme sind in hohem Maße auf umfassende und vielfältige Trainingsdaten angewiesen. Eine der größten Einschränkungen, auf die sie stoßen, ist jedoch der Mangel an hochwertigen Trainingsdaten. Ohne einen umfangreichen und vielfältigen Datensatz haben diese Systeme möglicherweise Schwierigkeiten, verschiedene Arten von Inhalten genau zu erkennen und zu unterscheiden.
2. Die Grenzen von Sprachmodellen
Obwohl diese Modelle erhebliche Fortschritte bei der Verarbeitung und dem Verständnis natürlicher Sprache gemacht haben, haben sie immer noch Probleme mit kontextbezogenen Nuancen, Sarkasmus, Ironie und kulturellen Bezügen. Infolgedessen können sie die volle Bedeutung oder Absicht hinter bestimmten Phrasen oder Sätzen nicht erfassen, was zu Fehlklassifizierungen führen kann.
3. Ständig fortschreitende Schreibtechniken
Die dynamische Natur der KI-gesteuerten Inhaltserstellung erfordert eine ständige Aktualisierung und Verfeinerung der Erkennungsalgorithmen. Ohne regelmäßige Anpassungen besteht die Gefahr, dass die Inhaltserkennungsprogramme ins Hintertreffen geraten und bei der Identifizierung und Kennzeichnung problematischer Inhalte weniger effektiv werden.
Navigation durch die Zukunft der KI-Inhaltserkennung
KI-Inhaltsdetektoren haben sich zwar als wertvolle Werkzeuge zur Bekämpfung von Fehlinformationen und zur Wahrung der Online-Integrität erwiesen, doch ist es wichtig, ihre Grenzen zu erkennen und zu überwinden.
Die Verbesserung der Vielfalt der Trainingsdaten, die Verfeinerung von Sprachmodellen, um nuancierte Sprache besser zu verstehen, und die Einführung flexibler Aktualisierungsmechanismen sind wesentliche Schritte zur Verbesserung der Effektivität von KI-Inhaltsdetektoren.
Da die Zahl der KI-Inhalte weiter zunimmt, müssen die KI-Erkennungstechniken unbedingt weiterentwickelt werden, um eine sicherere und zuverlässigere digitale Landschaft zu gewährleisten.

Kommentar hinterlassen
Ihre E-Mail-Adresse wird nicht veröffentlicht. E-Mail ist optional. Erforderliche Felder sind mit * markiert

